Functionals¶
Here we’ll discuss our progress for each functional requirement.
Population generator¶
We had a rough start, since there was an inconsistency in the assignment. We wrote quite some code for this that was eventually not needed, since the assignment was changed.
After the change, we made reasonable progress and were able to implement all of the requested features. We finished quite early in the project and were able to use it during the development of multi region.
Checkpointing¶
Progress for this was rather consistent, until we had to write a ParaView plugin. Building and configuring ParaView turned out to be rather difficult, therefore the making of the paraview reader is put on hold. Meanwhile we have been working on an integration of checkpointing with our multi region functionality, this in combination with all the changes that will be made by MPI is not trivial, while the basis is there, the exact integration is not yet finished.
Multi region¶
We splitted this in two parts, as described in the assignment. Our goal here was to make an interface that is designed in such a way, that you wouldn’t notice the difference between the shared memory approach and the MPI approach. This had some serious consequences for the shared memory solution.
The first version was a shared-memory implementation. We had to rewrite the above mentioned interface 3 times. This was due to some misunderstandings and miscommunications. We’ve almost finished this. However, we still have to decide on the configuration.
As is discussed in our test plan, we were planning to create a unified interface for both our shared-memory implementation and our MPI implementation. This interface, which we called AsyncSimulator, has been (and still is) a point of heavy discussion. It makes extensive use of std::future to provide the needed parallelism.
We are now working on a prototype for the MPI part of multi region.
This prototype is almost finished but at the moment we only send messages between processes.
The messaging between real life computers is still a work in progress.
Besides this we also need to determine how we use std::future in this specific situation.
TBB (UniPar)¶
First, we made a prototype to familiarize ourselves with both OpenMP and TBB. The prototype also showed a small performance increase in favour of TBB. However, a second prototype that was more in line with how OpenMP was used in the main project showed equal performance for both OpenMP and TBB.
We decided to first develop our code for unifying both parallelisation libraries in the prototype. At that point, we also devised a name for our little library: UniPar, short for Unified Parallelisation. It makes extensive use of templates (including parameter packs) and lambda’s (including std::forward). In our prototype, performance was identical between the different versions. (The entire table can be found here.)
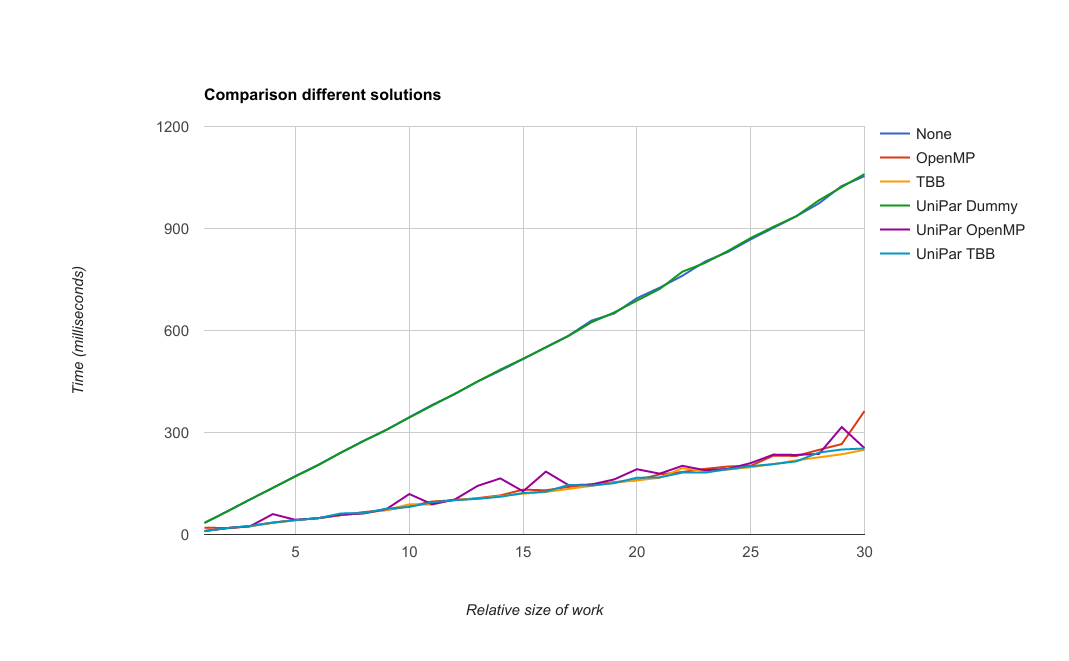
Then we placed the UniPar library in the main Stride project. This did bring up some issues. The biggest one is the fact that TBB is a bit more high-level that OpenMP. The loop that used OpenMP in Stride, made use of an RngHandler. Those are kept in a vector, one for each thread. This vector is then indexed using omp_get_thread_num(). However, in TBB this function was (as advised by the OpenMP group at Intel) purposefully removed. This gave us two options; either provide our own way of getting a thread number in TBB (which would be against TBB’s way of working), or devise another way of providing random numbers.
We went with the second option. A ResourceManager class was added to UniPar (not directly visible for clients). This uses std::function to provide the requested resource on demand. However, this meant we had to rewrite some stuff in Stride. After multiple tries, we settled on a method without RngHandler, using Random directly. A new problem showed: although our “Dummy” implementation (without parallelisation) passed all tests, our TBB and OpemMP versions did not. The reason for this is that the previous OpenMP implementation, even though multithreading is inherently nondeterministic, it did however provide “enough” determinism for much narrower limits on the results (i.e. getInfectedCount).
To verify that our implementation wasn’t at fault, we tested the original OpenMP implementation with the default configuration (taken from the tests) on 500 random seeds generated by std::random_device (very much like our own UniPar implementation). The results were as follows (for day 30):
- Average: 78187
- Standard deviation: 5983
- Minimum: 56116 (70000 - 56116 = 13884)
- Maximum: 108126 (108126 - 70000 = 38126)
This shows us that when using random seeds, we are better off using an expected number of cases of 80000 with a tolerated difference of 30000.
Scientific visualization¶
We have chosen for a lot of technologies to help build our visualization tool. We use electron to build a native cross-platform desktop application with web technologies like javascript and css. Electron is able of extracting a buildable executable tool which is what we want for our visualization tool. Due to usage of web technologies we have access to a number of useful libraries. We use mapbox for the mapview, plotly for elegant graphs, angularjs for the dynamic content of our tool and material design lite for the overall styling. Once we were all acquainted with these new languages development went very smooth.
The development of the tool is in its final stages, but we risk spending a lot of time on this, since visualizing is just so fun and rewarding.